 Colaboradores - Cristiano Lehrer
Colaboradores - Cristiano LehrerLehrer, Cristiano; Borges, Paulo Sergio da Silva. Algoritmos Genéticos com Operador de Recombinação Variável. Trabalho apresentado no II Congresso Brasileiro de Computação, Itajaí/SC, 2002. 12 páginas.
Alguns conceitos da teoria da seleção sexual são empregados para testar como eles podem aprimorar a atuação dos operadores genéticos utilizados em Algoritmos Genéticos (AG). O emprego de critérios racionais pode fornecer uma eficiência adicional aos AG na busca de soluções satisfatórias para problemas difíceis. Neste caso, os operadores tradicionais dos AG, especialmente o operador de recombinação, não contariam somente com critérios aleatórios para realizar a exploração da superfície adaptativa. Esta ideia é implementada através da geração de uma taxa de recombinação, para cada par de cromossomos que se apresenta ao operador de recombinação, utilizando informações provenientes dos cromossomos. Para testar o método, o Problema do Caixeiro Viajante é utilizado como plataforma de testes. Uma série de simulações são realizadas e os resultados alcançados apresentados e comparados com o método usual para o operador de recombinação. Algumas evidências indicam vantagens no uso da metodologia pesquisada.
Some concepts of the theory of the sexual selection are employed to test how they can improve the performance of the operators used in Genetic Algorithms (GA). The use of rational strategies can provide additional efficiency to the GA regarding the search of satisfactory solutions to difficult problems. In this case, the traditional GA operators, especially crossover operator, will no more rely solely on random criteria to carry out the exploration of the fitness landscape. This idea is implemented through the generation of crossover rate, for each pair of chromosomes that comes to the crossover operator, using coming information of the chromosomes. To test the method, the Traveling Salesman Problem has been used. A program of simulations has been run and the achieved results are presented especially some comparisons between the usual methods regarding the GA operators. Some evidence has been found that indicates the advantage of the investigated methodology.
A Biologia Evolucionária é uma forte fonte de inspiração para resolver problemas complexos, os quais requerem uma busca em um vasto campo de soluções possíveis (Mitchell, 1999).
A própria natureza teve que realizar uma busca em um enorme conjunto de soluções possíveis, as sequências genéticas, para desenvolver organismos aptos a viver e a se reproduzir em seus ambientes (Mitchell, 1996).
Os Algoritmos Genéticos (AG) são métodos baseados nos princípios da seleção natural e da sobrevivência do mais apto, simulando o processo de evolução natural para desenvolver soluções para problemas práticos (Beasley, 1993). A estes princípios são acrescentados os conceitos iniciados por Mendel, referentes à hereditariedade e à estrutura genética dos seres vivos (Smith, 2000).
Na maioria das implementações de AG, os parâmetros utilizados pelos operadores genéticos, em especial a taxa de recombinação - crossover, são definidos a priori e mantêm-se fixos durante toda a execução do algoritmo, sem considerar as particularidades dos indivíduos que serão submetidos aos operadores.
Na natureza, a probabilidade de que dois indivíduos gerem descendentes é calculada com base na análise das características dos indivíduos. Cada indivíduo possui algum critério de avaliação para comparar seus pretendentes, de modo a obter o melhor pretendente disponível (Miller, 2000).
Alguns indivíduos podem estar procurando parceiros com (a) preferências semelhantes às suas, com (b) preferências totalmente opostas, ou ainda com (c) preferências nem muito iguais e nem muito diferentes.
O presente trabalho apresenta alternativas ao operador de recombinação, propondo que os seus parâmetros sejam regulados pela distância entre os índices de adaptabilidade dos indivíduos escolhidos para a operação de recombinação.
Inspirados nos conceitos da genética e da Teoria da Seleção Natural de Charles Darwin, os Algoritmos Genéticos (AG) são um poderoso mecanismo de busca de soluções e uma das técnicas que compõem a Computação Evolucionária (Goldberg, 1989).
Propostos por John Holland entre os anos 1960 e 1970 na Universidade de Michigan, os AG são uma abstração da evolução biológica. A base teórica dos AG é apresentada no seu livro Adaptation in Natural Artificial and Systems (Holland, 1975).
O objetivo principal de Holland não era o desenvolvimento de algoritmos para resolver problemas específicos, mas um estudo formal do fenômeno da adaptação que acontece na natureza, e desenvolver um modo em que os mecanismos da adaptação natural pudessem ser incorporados pelos computadores (Mitchell, 1996).
Frequentemente visto como métodos de otimização, os AG podem ser aplicados num grupo de problemas que cresce a cada dia (Whitley, 1994), incluindo sistemas sociais, ecologia, economia, evolução do aprendizado e várias outras áreas do conhecimento (Mitchell, 1996).
Conforme a definição de Koza (1990), um AG é um algoritmo matemático altamente paralelo que transforma populações de objetos matemáticos individuais em novas populações utilizando operações genéticas, como a reprodução sexual (recombinação), e a reprodução proporcional a adaptabilidade, que é o princípio Darwiniano da sobrevivência do mais apto.
O conjunto de dados representado por um particular cromossomo é definido como genótipo, e contem as informações necessárias para a construção de um organismo, definido como fenótipo. A adaptabilidade ou aptidão (do inglês fitness) do indivíduo como solução do problema, depende da ação do fenótipo que pode ser deduzido através do genótipo, isto é, ele pode ser calculado com base no cromossomo utilizando uma função de adaptabilidade ou função de fitness (Beasley, 1993).
A implementação de um AG inicia com a criação de uma população inicial de cromossomos, cada indivíduo desta população é avaliado segundo sua adaptabilidade, que permitirá definir a probabilidade que cada indivíduo tem de gerar descendentes. Os operadores de seleção, recombinação e mutação são aplicados sobre a população de modo a gerar uma nova, que será a população inicial na próxima iteração. O processo é repetido até que soluções satisfatórias ou um número máximo de gerações sejam alcançados (Koza, 1992).
A operação de seleção consiste na escolha de dois cromossomos da população, chamados de pais, que serão submetidos a operação de recombinação, gerando os descendentes. O método normalmente utilizado é o da Roleta, que consiste na atribuição, a cada cromossomo, de um setor da Roleta proporcional a sua adaptabilidade, de forma que os mais aptos tenham mais chances de serem selecionados como pais (Coello, 1995).
A operação de recombinação, também conhecida como crossover, consiste na troca de partes do genótipo de dois pais para gerar dois novos descendentes. O método usual é a utilização de um único ponto de corte escolhido aleatoriamente, que divide o cromossomo em duas partes. Caso a operação não ocorra, os descendentes serão cópias exatas dos pais (Mitchell, 1996).
A operação de mutação altera aleatoriamente os valores de alguns genes do cromossomo. A probabilidade de acontecer a operação normalmente é muito pequena, por volta de 1% para cada gene (Whitley, 1994).
Neste artigo são apresentados três métodos para a operação de recombinação, sugeridos por Vieira (2000), que utilizando informações provenientes dos cromossomos, buscam obter a melhor taxa de recombinação sobre os dois indivíduos em análise.
Os métodos atuam diretamente sobre a probabilidade da operação de recombinação, utilizando os valores de aptidão (fitness) de um par de cromossomos (x e y), previamente selecionados pelo operador de seleção, para auferir o valor da probabilidade de ocorrência da operação de recombinação.
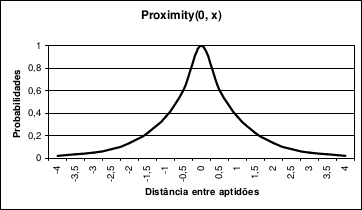
O primeiro método é chamado de Proximity, utilizando a seguinte função para auferir as probabilidades de ocorrência do operador:
Proximity(x, y) = e-|x-y| (Equação 1)
O método Proximity utiliza uma função simétrica para calcular as probabilidades de ocorrência, ou seja, conforme o valor da adaptabilidade do indivíduo x se aproxima do valor da adaptabilidade do indivíduo y a equação tenderá a 1, seu valor máximo.
Num contexto biológico se pode afirmar que o método Proximity beneficia pares de indivíduos com preferências ou personalidades semelhantes, dando-lhes uma probabilidade de gerarem descendentes maior do que a de casais com preferências opostas.
A Figura 1 ilustra o comportamento da função utilizada pelo método Proximity. Os valores utilizados são normalizados entre quatro negativo e quatro positivo, e uma das variáveis é fixada em zero, para efeito de visualização.
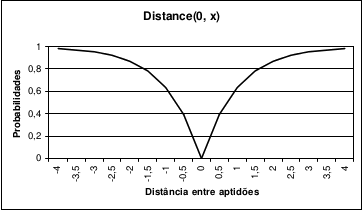
O segundo método proposto é Distance, utilizando a seguinte equação para calcular as probabilidades de ocorrência do operador:
Distance(x, y) = 1 - Proximity(x, y) (Equação 2)
O método Distance, da mesma forma que o método Proximity, utiliza uma equação simétrica, com valores inversamente proporcionais aos fornecidos pelo método Proximity, ou seja, conforme o valor da adaptabilidade do indivíduo x se afasta do valor da adaptabilidade do indivíduo y, a função tenderá a 1.
Num contexto biológico se pode afirmar que o método Distance beneficia pares de indivíduos com preferências ou personalidades opostas, dando-lhes uma probabilidade de gerarem descendentes maior do que a de casais com preferências semelhantes. O método Distance é uma abstração do velho ditado popular: "Os opostos se atraem!".
A Figura 2 ilustra o comportamento da função utilizada pelo método Distance. Os valores utilizados são normalizados entre quatro negativo e quatro positivo, e uma das variáveis é fixada em zero, para efeito de visualização.
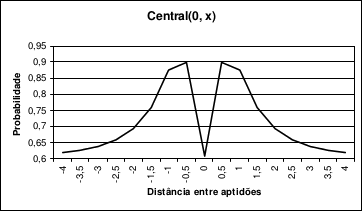
O último método proposto é o Central, que se utiliza da seguinte função para calcular a probabilidade de ocorrência do operador recombinação sobre um par de indivíduos:
Central(x, y) = e-|0,5 - Proximity(x, y)| (Equação 3)
O método Central beneficia pares de indivíduos cujos valores de adaptabilidade não sejam nem muito semelhantes e nem muito diferentes, ou seja, os valores de adaptabilidade devem estar num meio termo entre os extremos.
Em um contexto biológico se pode afirmar que o método Central beneficia pares de indivíduos que possuam algumas preferências iguais e ao mesmo tempo possuam algumas preferências opostas, dando-lhes uma maior probabilidade de gerarem descendentes. Essa função procura representar que indivíduos com aptidões nem muito semelhantes e nem muito opostas, ou em outras situações, com certas características semelhantes, mas, ao mesmo tempo, com outras características opostas, tenham uma maior probabilidade de gerarem descendente.
O método Central nunca fornece uma probabilidade de ocorrência da operação de recombinação para um par de indivíduos menor do que (0,6), em oposição aos demais métodos propostos que podem fornecer valores abaixo de (0,6), inclusive zero.
A Figura 3 ilustra o comportamento da função utilizada pelo método Central. Os valores utilizados são normalizados entre quatro negativo e quatro positivo, e uma das variáveis é fixada em zero, para efeito de visualização.
Conforme exibido nas figuras acima, os valores fornecidos como resposta pelos métodos propostos variam entre zero (0%) e um (100%). Como os métodos propostos se baseiam na diferença entre duas aptidões, e os valores auferidos para a adaptabilidade de cada cromossomo podem variar entre zero e mais infinito, é necessário normalizar a diferença entre as aptidões, que nos métodos propostos são normalizados entre zero e quatro.
Aos métodos propostos é acrescentado ainda um modificador, chamado de operação forçada. A utilização desse modificador inibe que os pais sejam copiados na nova população caso a operação de recombinação não ocorra, não permitindo que os filhos sejam cópias idênticas dos seus respectivos pais, possibilitando uma maior variedade genética.
Os métodos propostos são comparados com o método tradicional, que utiliza taxas fixas para a operação de recombinação. A plataforma de teste utilizado é o Problema do Caixeiro Viajante (Buriol, 2000), (West, 1994), com uma instância de 58 cidades com distâncias simétricas (TSPLIB, 2001).
A base de dados é criada armazenando, para cada execução de um AG empregando algum dos métodos de recombinação propostos, a menor distância encontrada e a geração onde essa distância apareceu na população pela primeira vez, objetivando observar a qualidade das respostas encontradas e o desempenho dos métodos.
A análise dos métodos será realizada em duas etapas. A primeira etapa objetiva encontrar a melhor configuração de parâmetros para o método em análise, através da análise da superfície de resposta fornecido pelo método utilizando várias configurações de parâmetros.
Utilizando a configuração de parâmetros fornecida pela primeira etapa, são geradas 1.000 novas amostras, que formarão a base de dados a ser utilizada na análise descritiva, utilizada para comparar os resultados dos métodos.
As execuções se iniciam sempre com uma população inicial criada aleatoriamente e uma cidade de origem definida também de modo aleatório. Dentre os vários parâmetros que podem ser manipulados num AG, os seguintes são mantidos fixos em todas as execuções:
Com o objetivo de encontrar o conjunto de parâmetros que produza o melhor resultado, são geradas 100 amostras para cada combinação dos parâmetros abaixo relacionados:
Para o método tradicional são geradas 1.200 amostras para a primeira etapa da análise, uma vez que existem 12 combinações possíveis entre os parâmetros utilizados. Para os métodos propostos são geradas apenas 300 amostras para a primeira etapa da análise, uma vez que apenas o parâmetro taxa de mutação é necessário.
A Tabela 1 apresenta uma análise descritiva da variável distância para as amostras geradas para a primeira etapa. Uma análise superficial dos resultados apresentados indica que dentre os métodos propostos, o método Distance com operação forçada obteve uma melhor qualidade nas respostas, com um desempenho superior de aproximadamente 4,50% sobre o método Tradicional e 2,88% sobre o método Tradicional utilizando a operação forçada.
| Métodos | Média | Desvio Padrão | Valor Mínimo | Valor Máximo |
|---|---|---|---|---|
| Tradicional | 44.206,87 | 3.789,93 | 32.906 | 54.033 |
| Tradicional - forçada | 43.469,98 | 3.852,15 | 32.913 | 56.642 |
| Proximity | 42.930,11 | 3.844,71 | 31.882 | 55.032 |
| Proximity - forçada | 53.657,42 | 9.684,90 | 35.574 | 75.570 |
| Distance | 46.010,94 | 4.227,09 | 36.699 | 57.362 |
| Distance - forçada | 42.218,78 | 3.324,46 | 33.204 | 53.869 |
| Central | 44.030,25 | 3.721,39 | 34.875 | 52.416 |
| Central - forçada | 43.274,81 | 3.906,60 | 33.089 | 53.866 |
A Tabela 2 apresenta os parâmetros utilizados pelos métodos para formar a base de dados utilizada na segunda etapa da análise, base de dados obtida através da execução de 1.000 amostras para cada método utilizando sua respectiva configuração de parâmetros.
| Métodos | População | Gerações | Recombinação | Mutação |
|---|---|---|---|---|
| Tradicional | 100 | 5.000 | 0,8 | 0,005 |
| Tradicional - forçada | 100 | 5.000 | 0,5 | 0,005 |
| Proximity | 100 | 5.000 | - | 0,005 |
| Proximity - forçada | 100 | 5.000 | - | 0,005 |
| Distance | 100 | 5.000 | - | 0,005 |
| Distance - forçada | 100 | 5.000 | - | 0,005 |
| Central | 100 | 5.000 | - | 0,005 |
| Central - forçada | 100 | 5.000 | - | 0,005 |
A Tabela 3 apresenta a análise descritiva da variável geração para os dados obtidos na segunda etapa. Essa análise objetiva avaliar o desempenho dos métodos quanto ao número de gerações necessários, em média, para encontrar a menor distância.
| Métodos | Média | Desvio Padrão | Valor Mínimo | Valor Máximo |
|---|---|---|---|---|
| Tradicional | 3.918,56 | 957,07 | 922 | 5.000 |
| Tradicional - forçada | 3.969,67 | 936,40 | 1.000 | 5.000 |
| Proximity | 4.100,84 | 838,30 | 1.257 | 5.000 |
| Proximity - forçada | 4.092,65 | 827,18 | 998 | 5.000 |
| Distance | 3.836,00 | 972,81 | 560 | 5.000 |
| Distance - forçada | 3.953,21 | 939,02 | 453 | 5.000 |
| Central | 3.957,26 | 909,68 | 575 | 5.000 |
| Central - forçada | 3.926,05 | 905,15 | 864 | 5.000 |
Conforme apresentado na Tabela 3, o método Distance necessita, em média, de um número de gerações menor do que os dos demais métodos para encontrar a resposta, com um desempenho superior de aproximadamente 2,10% sobre o método Tradicional, seguido pelo próprio.
Entretanto, o método Distance apresenta também o maior desvio-padrão dos resultados dentre os métodos analisados, apresentando um valor aproximadamente 1,57% maior do que o apresentado pelo método Tradicional, e ainda 14,97% maior do que o menor valor apresentado, obtido pelo método Proximity com operação forçada.
A Tabela 4 apresenta a análise descritiva da variável distância para os dados obtidos na segunda etapa. Essa análise objetiva avaliar o desempenho dos métodos quanto a qualidade das respostas encontradas, buscando o método que encontre as menores distâncias, uma vez que a plataforma de teste é um problema de minimização.
| Métodos | Média | Desvio Padrão | Valor Mínimo | Valor Máximo |
|---|---|---|---|---|
| Tradicional | 40.878,47 | 3.163,35 | 31.634 | 50.108 |
| Tradicional - forçada | 40.644,92 | 3.081,16 | 32.680 | 52.693 |
| Proximity | 40.596,29 | 3.091,21 | 32.201 | 54.419 |
| Proximity - forçada | 42.844,01 | 3.371,79 | 33.707 | 53.628 |
| Distance | 43.479,15 | 3.028,94 | 35.534 | 53.285 |
| Distance - forçada | 40.270,53 | 3.000,78 | 31.952 | 52.472 |
| Central | 41.052,70 | 3.165,18 | 33.333 | 52.826 |
| Central - forçada | 40.248,44 | 3.082,11 | 33.466 | 50.770 |
Conforme os resultados apresentados na Tabela 4, o método com o melhor desempenho sobre o método Tradicional é o método Central com operação forçada, com uma melhoria de 1,54%. Em seguida, o método Distance com operação forçada e o método Proximity (vantagens de 1,48% e 0,69% respectivamente). Os demais métodos apresentaram resultados inferiores aos do método Tradicional.
Em comparação com o método Tradicional com operação forçada, que obteve uma melhora de 0,57% sobre o método Tradicional puro, os desempenhos alcançados pelos métodos propostos sofrem uma redução. O método Central com operação forçada alcança uma melhora de 0,97%, o método Distance com operação forçada 0,92% e o Proximity 0,11%. Os métodos que apresentaram os melhores resultados também apresentaram os menores desvios padrões, confirmando o melhor desempenho sobre o método Tradicional.
A utilização de critérios racionais para especificar a taxa de ocorrência da operação de recombinação, considerando características dos indivíduos envolvidos na operação, procura tornar a busca por soluções satisfatórias na superfície adaptativa uma atividade mais eficiente do que as utilizadas pelos métodos convencionais.
Os métodos propostos eliminam a necessidade de se especificar uma taxa, a priori, para a operação de recombinação, que na maioria dos casos é estimada com base na experiência pessoal do pesquisador, auxiliando que resultados mais significativos ou idênticos aos encontrados pelo método tradicional, sejam apresentados sem a necessidade de se experimentar ou estimar várias taxas, até que a mais adequada ao problema em questão seja especificada.
Os métodos propostos para a operação de recombinação foram avaliados em um domínio de problema, havendo a necessidade de serem avaliados sobre outros domínios, para se averiguar o real desempenho dos métodos.
Beasley, David. (1993). An Overview of Genetic Algorithms: Part 1, Fundamentals. In University Computing 15 (2), 58-69. 12 pages.
Buriol, Luciana Salete. (2000). Algoritmo Memético para o Problema do Caixeiro Viajante Assimétrico como Parte de um Framework para Algoritmos Evolutivos. Dissertação de Mestrado, Universidade Estadual de Campinas, Departamento de Engenharia de Sistemas, Faculdade de Engenharia Elétrica e de Computação, UNICAMP, Campinas, São Paulo.
Coello, Carlos Artemio Coello. (1995). Introducción a los Algoritmos Genéticos. In Soluciones Avanzadas: tecnologías de información y estrategias de negocios 3 (17), 5-11. 7 pages.
Goldberg, David Edward. (1989). Genetic Algorithms in Search, Optimization, and Machine Learning. Addison-Wesley Publishing Company, Inc. 412 pages.
Holland, John Henry. (1975). Adaptation in Natural and Artificial Systems. University of Michigan Press. 211 pages.
Koza, John R. (1992). Genetic Programming: on the programming of computers by means of natural selection. A Broad Book. 840 pages.
Miller, Geoffrey F. (2000). A Mente Seletiva: como a escolha sexual influencia a evolução da natureza humana. Rio de Janeiro: Campus. 422 páginas.
Mitchell, Melanie. (1996). An Introduction to Genetic Algorithms. Cambridge: MIT Press. 221 pages.
Mitchell, Melanie. (1999). Evolutionary Computation: an overview. In Annual Review of Ecology and Systematics, 20, 593-616. 24 pages.
Smith, John Maynard. (2000). The Theory of Evolution. Cambridge, University Press. 380 pages.
TSPLIB (2001). Traveling Salesman Problem Library. Acessado em Dezembro de 2001.
Vieira, Richard G. S. (2000). Algoritmos Genéticos com Probabilidade de Crossover Variável. Artigo Técnico Interno. Florianópolis: Pós-Graduação em Ciência da Computação.
West, Douglas Brent. (1996). Introduction to Graph Theory. Upper Saddle River: Prentice Hall, Inc. 470 pages.
Whitley, Darrell. (1994). A Genetic Algorithm Tutorial. In Statistics and Computing 4, 65-85. 37 pages.
Artigo científico apresentado no II Congresso Brasileiro de Computação
Ybadoo - Soluções em Software Livre • Copyright 2009/2026 • ![]()